|
Jak jste pocítili hospodářskou krizi v roce 2009? celkem se účastnilo: 196105 
|

5.04.2009 ANALÝZA: Analýza věkových struktur historických populací V předkládaném textu se tým autorů zabývá různými matematickými a statistickými přístupy k analýze věkových struktur historických populací. Eva Kačerová, Jiří Henzler i Jovan Kubíček působí na VŠE v Praze a problematice se dlouhodobě věnují. V předkládaném textu se tým autorů zabývá různými matematickými a statistickými přístupy k analýze věkových struktur historických populací. Eva Kačerová, Jiří Henzler i Jovan Kubíček působí na VŠE v Praze a problematice se dlouhodobě věnují.1. ÚvodČlánek volně navazuje na analýzy již zveřejněné v sekci historická demografie.Základním pramenem pro studium složení obyvatelstva podle věku a pohlaví v Chrudimském kraji v polovině 17. století je Soupis poddaných podle víry z roku 1651 (Pazderová, 2002), jehož vznik souvisí s rekatolizačními snahami po třicetileté válce. Impulsem ke zhotovení Soupisu byl patent českých místodržících ze dne 16. listopadu 1650, který byl vydán 4. února 1651. Konstatovala se v něm nedokonalost dosavadních soupisů nekatolických poddaných a nařizovalo se všem vrchnostem, aby podle přiloženého formuláře uvedly „všechny lidi poddané obojího pohlaví v jistou a hodnověrnou specifikaci“, již měli krajští hejtmané odeslat do šesti neděl české kanceláři. Podle Soupisu žilo na Chrudimsku 46626 osob, z toho 24860 žen. U 2104 osob nebyl údaj o věku zapsán. Děti mladší 12 let byly evidovány zřídka. Na žádném z panství Chrudimského kraje nebyla evidence dětí „předzpovědního“ věku úplná, a tak k odhadu počtu dětí mladších 10 resp. 12 let by musela být užita analogie s jiným krajem (není předmětem tohoto článku). Pro studium demografické struktury je velice důležitý údaj o věku, který je čtvrtou kategorií Soupisu. Přesný věk nebyl příliš důležitý pro účel, za kterým Soupis vznikal, a hrál spíše podružnou roli. I přes zjevné nepřesnosti a zaokrouhlování představuje cennou informaci (graf1). Písaři měli tendenci věk těch, kteří jej neznali přesně, zaokrouhlovat na násobky 10 či 5. Větší oblibu než lichá čísla měla čísla sudá. Ve věku mladším 30 let by se dalo hovořit i o zaokrouhlování vlivem šedesátkové soustavy. Zajímavá je také souvislost věku s některými sociálními kategoriemi. Vdovám podruhyním se často připisoval věk 40 let, pokud byly starší tak 60 let. U „žen samotných“ majících děti, tedy pravděpodobně svobodných matek, zase často najdeme věk 30 let a podobně. Míru zkreslení lze měřit indexem věkové kumulace ik: 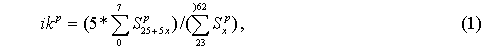 kde Sx představuje počet osob v dané věkové skupině a horní index p je pohlaví. Zaokrouhlování věku se negativně promítne do výsledků studia věkové struktury obyvatelstva. Toto zkreslení lze zmenšit používáním desetiletých věkových intervalů, v nichž bude nejfrekventovanější hodnota vždy uprostřed, tedy 5–14, 15–24, atd. (graf2). Pro možnost srovnání s dnešní statistikou i ostatními autory zabývajícími se rozborem Soupisu poddaných podle víry z roku 1651 je potřeba zachovat také obvyklé věkové intervaly: 0–4, 5–9, 10–14, atd. (graf3). V některých studiích se ještě můžeme setkat s desetiletými intervaly 0–9, 10–19, atd.. Volba věkových intervalů může ovlivnit význam zaokrouhlování ve výsledné věkové struktuře. V každém případě však vede ke ztrátě informace. 2. Klouzavé průměryStandardní statistickou technikou je vyhlazení dat pomocí klouzavých průměrů. Protože nejčetnější zaokrouhlování se dělo na celé desítky, přichází v úvahu klouzavé průměry deseti po sobě jdoucích hodnot. Věkové skupiny mladší 12 let jsou v datovém souboru výrazně podhodnoceny, ať už proto, že děti nebyly zaznamenávány, nebo byly údaje o 10 a 11letých zahrnuty do kategorie zpovědního věku 12 let. Proto nebyly údaje pro věk nižší než 12 let začleněny do zpracování. Aby v následujících věkových kategoriích nedošlo absencí dat pod 12 let ke zkreslení tvaru věkové pyramidy, je pro kategorie 12 až 16 let, kde by klouzavý průměr deseti po sobě jdoucích hodnot zasahoval do věku pod 12 let, počítán klouzavý průměr z kratšího časového úseku: pro kategorii 12 let je nahrazen zjištěnou hodnotou, pro kategorii 13 let je nahrazen aritmetickým průměrem hodnot v kategoriích 12, 13, 14, pro 14 let aritmetickým průměrem dat z věku 12, 13, 14, 15, 16, pro 15 let průměrem z dat pro věk 12, 13, 14, 15, 16, 17, 18 a konečně pro 16 let průměrem z dat pro věk 12, 13, 14, 15, 16, 17, 18, 19, 20. Od 17 let počínaje budou data nahrazena klouzavými průměry deseti hodnot. Aby byla zajištěna symetrie ohledně nahrazované hodnoty, nahradí se data v kategorii k let, k>17, aritmetickým průměrem dvou následujících klouzavých průměrů: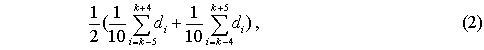 kde d(i) je zjištěná hodnota pro věk (i) (graf 4). 3. Matematické modelyDalší možností je vytvořit jednoduchý matematický model předpokládající, že zaokrouhlování vykazuje určitou zákonitost. Pokud teoretická data získaná na základě takového modelu nebudou vykazovat systematickou chybu, můžeme na základě použitého modelu vyslovit hypotézu o možném způsobu zaokrouhlování.V této stati autoři předkládají dva matematické modely. V obou se předpokládá, že na celé desítky se zaokrouhluje věk nejvýše o 4 roky větší a nejvýše o 4 roky menší, na hodnoty zakončené 5 se zaokrouhluje věk nejvýše o 2 roky větší a nejvýše o 2 roky menší, na sudá čísla se zaokrouhluje věk nejvýše o 1 rok větší a nejvýše o 1 rok menší. Zaokrouhlování na čísla dělitelná 6 nebylo v těchto modelech zohledněno, jelikož vzhledem k několika málo hodnotám, které přicházely v úvahu (18, 24, 30), by nebylo možné odhadnout systematickou chybu modelu. V obou modelech byl však navíc vzat v úvahu zajímavý fenomén zřejmý z výchozí věkové struktury (graf 1), že totiž počínaje věkem 24 je věk zakončený na 6 výrazně četnější (někde více než dvojnásobně) než věk zakončený na 4. To mohlo být způsobeno tím, že v případě věku 23, 33 atd. bylo zaokrouhlováno nahoru nikoli na 24, 34 atd., ale přímo na 25, 35 atd. a dále že věk 25, 35 atd. byl zaokrouhlován pouze nahoru na 26, 36 atd. a nikoli naopak. Aby bylo možné odhadnout četnosti h(10), h(5), h(3), které v empirických hodnotách věku zakončených na 0, 5 a sudé číslo připadaly na zaokrouhlení, a odtud z empirických hodnot y(i) odhadnout teoretické hodnoty Y(i), předpokládalo se v obou modelech, že se sousední teoretické hodnoty věku Y(28), Y(29), Y(30), Y(31), Y(32), liší o stejnou hodnotu Δ, stejně tak hodnoty Y(33), Y(34), Y(35), Y(36), Y(37), atd. Údaje o obyvatelích předzpovědního věku, tj. mladších 12 let, byly ze stejných důvodů jako v případě klouzavých průměrů z analýzy vyloučeny. Rovnoměrný modelV rovnoměrném modelu předpokládáme, že četnosti hodnot zaokrouhlených na věk zakončený 0, 5 a sudým číslem jsou pro všechny okolní zaokrouhlované hodnoty stejné. Například při zaokrouhlování na věk 30 byl zaokrouhlen stejný počet h10(30) osob o skutečném věku 26, 27, 28, 29, 31, 32, 33, 34, při zaokrouhlování na věk 35 byl zaokrouhlen stejný počet h5(35) osob o skutečném věku 33, 34, 37 (k věku 36 viz třetí odstavec předchozí části), atd.Z rovnic 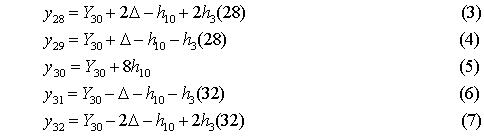 vypočteme neznámé Y30, h10, h3(28), h3(32), Δ a zbývající hodnoty Y28, Y29, Y31, Y32 a stejně postupujeme u obdobných rovnic pro y38, y39, y40, y41, y42, atd. Podobně vyřešíme soustavu 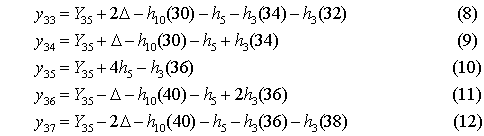 a obdobné soustavy pro y43, y44, y45, y46, y47 atd. (graf 5). Lineární modelV lineárním modelu se předpokládá, že četnosti hodnot zaokrouhlených na věk zakončený 0, 5 a sudým číslem jsou tím větší, čím je zaokrouhlovaná hodnota blíže k té, na kterou se zaokrouhluje. Například při zaokrouhlování na věk 30 by se zaokrouhlovalo h10(30) osob o skutečném věku 26 a 34, dvojnásobný počet osob 2h10(30) o skutečném věku 27 a 33, 3h10(30) osob o skutečném věku 28 a 32, a 4h10(30) osob o skutečném věku 29 a 31, a podobně při zaokrouhlování na věk 35 (zde se však zohlednil vliv fenoménu 34, 36) atd.Podobně jako v rovnoměrném modelu vycházíme z rovnic 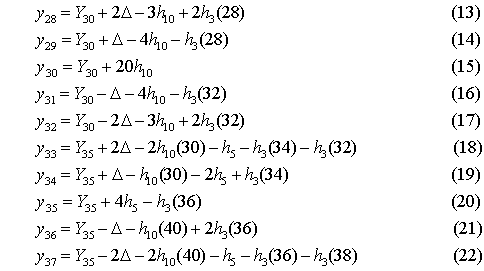 4. ZávěrZ obou teoretických bihistogramů (obr. 5 a 6) je patrné, že v případě studované populace vykazuje menší systematickou chybu (periodicitu teoretických dat) lineární model. V případě rovnoměrného modelu se zdá, že tento model věrněji vystihuje ženskou složku populace. Z bihistogramu na základě klouzavých průměrů si lze učinit pouze souhrnný pohled na danou populaci. Zásadní rozdíl mezi statistickým přístupem založeným na klouzavých průměrech a přístupem užívajícím jednoho nebo druhého modelu spočívá podle autorů v tom, že matematickými modely se do dat vnáší určité hypotézy založené zčásti na současných znalostech realizace takovýchto soupisů v 17. století, zatímco statistický přístup pracuje pouze z daty.Tento článek vznikl s podporou IGA VŠE 15/08 a MŠMT 2D06026. Graf1: Věková struktura obyvatel Chrudimského kraje dle Soupisu poddaných podle víry z roku 1651 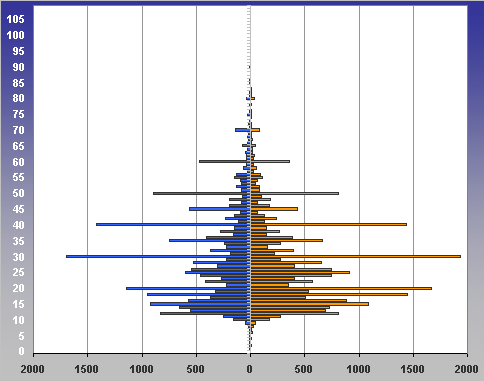 Graf2: Věková struktura obyvatel Chrudimského kraje dle Soupisu poddaných podle víry z roku 1651 (desetileté intervaly) 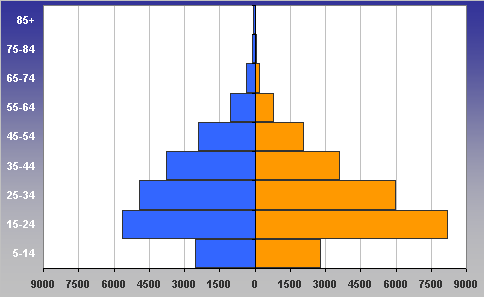 Graf3: Věková struktura obyvatel Chrudimského kraje dle Soupisu poddaných podle víry z roku 1651 (pětileté intervaly) 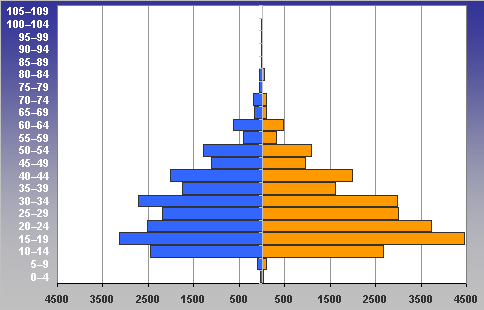 Graf4: Klouzavé průměry 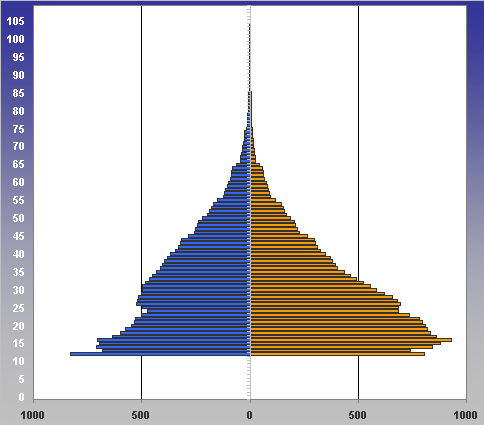 Graf5: Rovnoměrný model 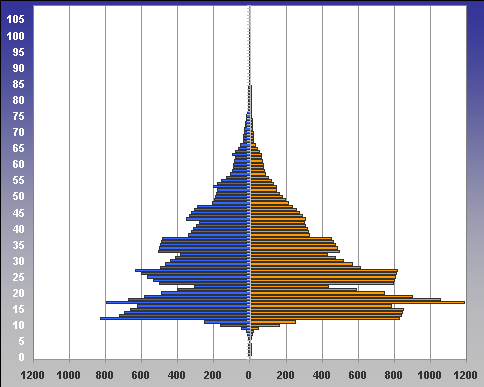 Graf6: Lineární model 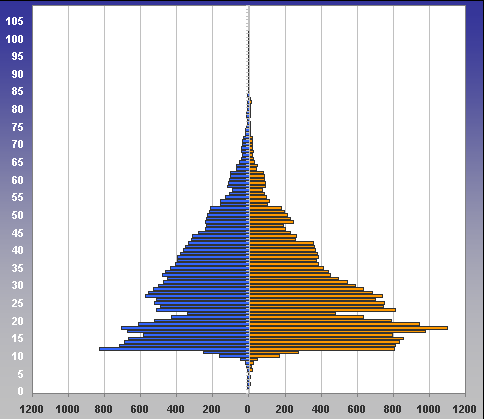 Literatura [1] Ducháček, K. – Fialová, L. – Horská, P. – Répásová, M. – Sládek, M.: On using the 1661–1839 lists of subject of the Třeboň dominion to study the age structure of the population, in: HD 13, 1989, s. 59–75. [2] Fialová, L. – Kučera, M. – Maur, E. – Horská, P. – Musil, J. – Stloukal, M.: Dějiny obyvatelstva českých zemí, Praha, 1998. [3] Henzler, J. a kolektiv: Matematika pro ekonomy, Oeconomica, Praha, 2007. [4] Kačerová, E.: Struktura obyvatelstva Choceňska v roce 1651, Demografie [online], 2008, s. 1–4, http://www.demografie. [5] Kačerová, E., Henzler, J.: Matematické modelování věkových struktur historických populací, in: Forum Statisticum Slovacum 1/2009, Nitra, 2009 [6]Maur, E.: Problémy demografické struktury Čech v polovině 17. století, in: ČsČH XIX, 1971, s. 849–850. [7] Pazderová, A.: Soupis poddaných podle víry – Chrudimsko, Národní archív, 2002. [8] Žváček, J. – Henzler, J.: Statistika pro ekonomy, interaktivní text na CD, MUP, Praha, 2009. Eva Kačerová Jiří Henzler Jovan Kubíček Eva Kačerová |
Prohledejte celý portál www.demografie.info
Výkladový slovník odborné demografické terminologie (české, anglické i francouzské pojmy)
V případě zájmu o aktuální dění z oblasti demografie zaregistrujte vaši emailovou adresu, na kterou vám budeme zasílat novinky.

1. dubna 2005 jsme spustili do provozu nový demografický informační portál. Je určen široké laické i odborné veřejnosti. Obraťte se na nás s jakýmkoli dotazem, či připomínkou. Za všechny reakce budeme vděční. Portál obsahuje velké množství informací, používejte proto prosím vyhledávání!
Vaš redakční tým |